(Comments)

Python 3.5, numpy, pickle, keras,
Customer hotel reviews, including
2916 positive reviews and 3000 negative reviews
Some data files contain abnormal encoding characters which encoding GB2312 will complain about. Solution: read as bytes then decode as GB2312 line by line, skip lines with abnormal encodings. We also convert any traditional Chinese characters to simplified Chinese characters.
documents = []
for filename in positiveFiles:
text = ""
with codecs.open(filename, "rb") as doc_file:
for line in doc_file:
try:
line = line.decode("GB2312")
except:
continue
text+=Converter('zh-hans').convert(line)
text = text.replace("\n", "")
text = text.replace("\r", "")
documents.append((text, "pos"))
Have those two files download from
langconv.py
zh_wiki.py
those two lines below will convert string "line" from traditional to simplified Chinese.
from langconv import *
Converter('zh-hans').convert(line)
Use
We then feed the string to Keras Tokenizer which
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
import jieba
seg_list = jieba.cut(text, cut_all=False)
text = " ".join(seg_list)
# totalX = [text , .....]
# maxLength is the sentence words length to keep
input_tokenizer = Tokenizer(30000)
input_tokenizer.fit_on_texts(totalX)
input_vocab_size = len(input_tokenizer.word_index) + 1
totalX = np.array(pad_sequences(input_tokenizer.texts_to_sequences(totalX), maxlen=maxLength))
First get a list of stop words from the file
stopwords = [ line.rstrip() for line in open('./data/chinese_stop_words.txt',"r", encoding="utf-8") ]
for doc in documents:
seg_list = jieba.cut(doc[0], cut_all=False)
final =[]
seg_list = list(seg_list)
for seg in seg_list:
if seg not in stopwords:
final.append(seg)
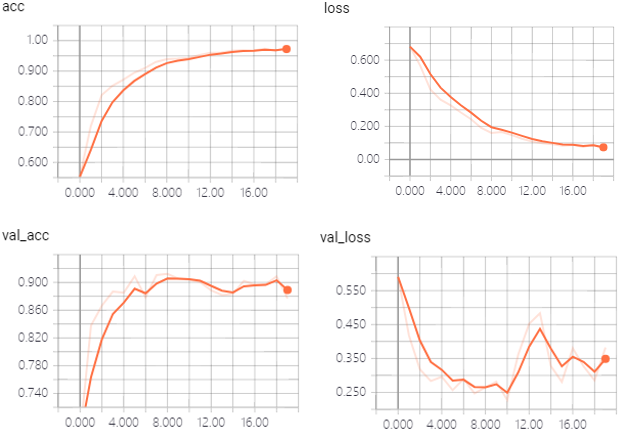
Keras trained for 20 epochs, takes 7 minutes 14 seconds with GPU (GTX 1070)
acc:0.9726

For the Python Jupyter notebook source code and dataset, check out my
For an updated word-level English model, check out my other blog: Simple Stock Sentiment Analysis with news data in Keras.
Share on Twitter Share on Facebook
Comments