(Comments)

My previous post shows how to choose last layer activation and loss functions for different tasks. This post we focus on the multi-class multi-label classification.
We are going to use the Reuters-21578 news dataset. With a given news, our task is to give it one or multiple tags. The dataset is divided into five main categories:
For example, one given news could have those 3 tags belonging two categories
| Name | Type | Newslines | |
|---|---|---|---|
| 619 | pl_usa | Places | 12542 |
| 35 | to_earn | Topics | 3987 |
| 0 | to_acq | Topics | 2448 |
| 616 | pl_uk | Places | 1489 |
| 542 | pl_japan | Places | 1138 |
| 489 | pl_canada | Places | 1104 |
| 73 | to_money-fx | Topics | 801 |
| 28 | to_crude | Topics | 634 |
| 45 | to_grain | Topics | 628 |
| 625 | pl_west-germany | Places | 567 |
| 126 | to_trade | Topics | 552 |
| 55 | to_interest | Topics | 513 |
| 514 | pl_france | Places | 469 |
| 412 | or_ec | Organizations | 349 |
| 481 | pl_brazil | Places | 332 |
| 130 | to_wheat | Topics | 306 |
| 108 | to_ship | Topics | 305 |
| 468 | pl_australia | Places | 270 |
| 19 | to_corn | Topics | 254 |
| 495 | pl_china | Places | 223 |
In previous step, we read the news contents and stored in a list
One news looks like this
average yen cd rates fall in latest week
tokyo, feb 27 - average interest rates on yen certificates
of deposit, cd, fell to 4.27 pct in the week ended february 25
from 4.32 pct the previous week, the bank of japan said.
new rates (previous in brackets), were -
average cd rates all banks 4.27 pct (4.32)
money market certificate, mmc, ceiling rates for the week
starting from march 2 3.52 pct (3.57)
average cd rates of city, trust and long-term banks
less than 60 days 4.33 pct (4.32)
60-90 days 4.13 pct (4.37)
average cd rates of city, trust and long-term banks
90-120 days 4.35 pct (4.30)
120-150 days 4.38 pct (4.29)
150-180 days unquoted (unquoted)
180-270 days 3.67 pct (unquoted)
over 270 days 4.01 pct (unquoted)
average yen bankers' acceptance rates of city, trust and
long-term banks
30 to less than 60 days unquoted (4.13)
60-90 days unquoted (unquoted)
90-120 days unquoted (unquoted)
reuter
We start up the cleaning up by
After this our news will looks much "friendly" to our model, each word is seperated by space.
average yen cd rate fall latest week tokyo feb 27 average interest rate yen certificatesof deposit cd fell 427 pct week ended february 25from 432 pct previous week bank japan said new rate previous bracket average cd rate bank 427 pct 432 money market certificate mmc ceiling rate weekstarting march 2 352 pct 357 average cd rate city trust longterm bank le 60 day 433 pct 432 6090 day 413 pct 437 average cd rate city trust longterm bank 90120 day 435 pct 430 120150 day 438 pct 429 150180 day unquoted unquoted 180270 day 367 pct unquoted 270 day 401 pct unquoted average yen banker acceptance rate city trust andlongterm bank 30 le 60 day unquoted 413 6090 day unquoted unquoted 90120 day unquoted unquoted reuter
Since a small portation of news are quite long even after the cleanup, let's set a limit to the maximum input sequence to 88 words, this will cover up 70% of all news in full length. We could have set a larger input sequence limit to cover more news but that will also increase the model training time.
Lastly, we will turn words into the form of ids and pad the sequence to input limit (88) if it is shorter.
Keras text processing makes this trivial.
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
max_vocab_size = 200000
input_tokenizer = Tokenizer(max_vocab_size)
input_tokenizer.fit_on_texts(totalX)
input_vocab_size = len(input_tokenizer.word_index) + 1
print("input_vocab_size:",input_vocab_size) # input_vocab_size: 167135
totalX = np.array(pad_sequences(input_tokenizer.texts_to_sequences(totalX),
maxlen=maxLength))
The same news will look like this, each number represents a unique word in the vocabulary.
array([ 6943, 5, 5525, 177, 22, 699, 13146, 1620, 32,
35130, 7, 130, 6482, 5, 8473, 301, 1764, 32,
364, 458, 794, 11, 442, 546, 131, 7180, 5,
5525, 18247, 131, 7451, 5, 8088, 301, 1764, 32,
364, 458, 794, 11, 21414, 131, 7452, 5, 4009,
35131, 131, 4864, 5, 6712, 35132, 131, 3530, 3530,
26347, 131, 5526, 5, 3530, 2965, 131, 7181, 5,
3530, 301, 149, 312, 1922, 32, 364, 458, 9332,
11, 76, 442, 546, 131, 3530, 7451, 18247, 131,
3530, 3530, 21414, 131, 3530, 3530, 3])
embedding_dim = 256
model = Sequential()
model.add(Embedding(input_vocab_size, embedding_dim,input_length = maxLength))
model.add(GRU(256, dropout=0.9, return_sequences=True))
model.add(GRU(256, dropout=0.9))
model.add(Dense(num_categories, activation='sigmoid'))
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
history = model.fit(totalX, totalY, validation_split=0.1, batch_size=128, epochs=10)
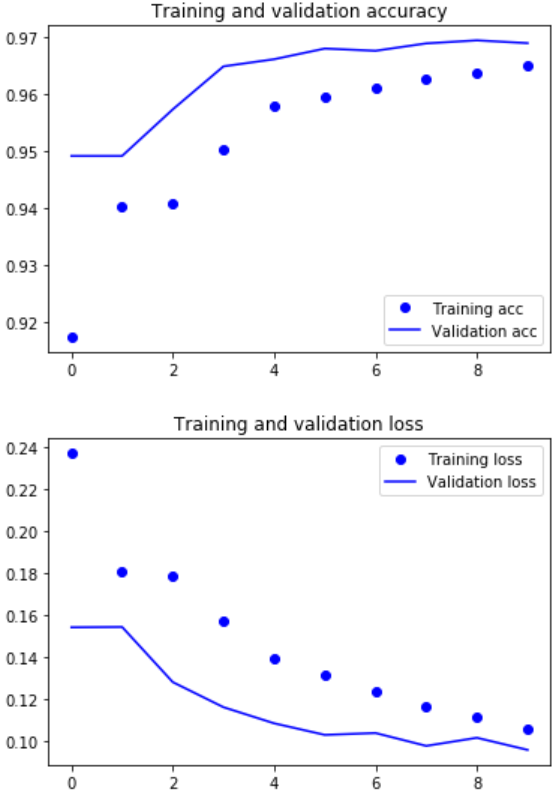
After training our model for 10 epochs in about 5 minutes, we have achieved the following result.
loss: 0.1062 - acc: 0.9650 - val_loss: 0.0961 - val_acc: 0.9690
The following code will generate a nice graph to visualize the progress of each training epochs.
import matplotlib.pyplot as plt
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc))
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
Take one cleaned up news (each word is separated by space) to the same input tokenizer turning it to ids.
Call the model predict method, the output will be a list of 20 float numbers representing probabilities to those 20 tags. For demo purpose, lets take any tags will probability larger than 0.2.
textArray = np.array(pad_sequences(input_tokenizer.texts_to_sequences([input_x_220]), maxlen=maxLength))
predicted = model.predict(textArray)[0]
for i, prob in enumerate(predicted):
if prob > 0.2:
print(selected_categories[i])
This produces three tags
pl_uk pl_japan to_money-fx
the ground truth is
pl_japan to_money-fx to_interest
The model got 2 out of 3 right for the given news.
We start with cleaning up the raw news data for the model input. Built a Keras model to do multi-class multi-label classification. Visualize the training result and make a prediction. Further improvements could be made
The source code for the jupyter notebook is available on my GitHub repo if you are interested.
Share on Twitter Share on Facebook
Comments